Nowadays using a scoped enum (enum class or enum struct) is pretty common. It has its clear benefits when writing type safe code [1]. This article is not about using scoped enums or not, since I don’t see any point in not using it. But instead this article is about how to use enum class together with bit flags or bit patters.
Enums are heavily used as bit flags in many software. I guess we all seen code that looks something like this.
enum {
Read = 1,
Write = 2,
Execute = 4
};
permission = Read | Write;
...
permission |= Execute
When working with embedded systems I stumbled across this both here and there. Either when working directly against some control register or some binary communication protocol, for naming just a few occasions.
Doing the same thing with scoped enum
One problem with the code snippet above is that it does not use scoped enum. Is it possible? Yes - if not this article would be pretty boring right!
The rest of this article is a simple example class (File). This class is part of an implementation of a file class but it just focus on the file permissions flags, nothing else. The example code is available at GitHub. Each step a the article has its separate branch.
Example
Start of the File class
Read full code on GitHub - branch: step-1
To start with we need to define our permissions as an enum.
enum class Permission { Read = 1, Write = 2, Execute = 4 }
Next we need a constructor.
File(const std::string &name, const Permission &permissions);
The goal is to be able to write code that looks like this:
File f2("/tmp/file1", File::Permission::Read |
File::Permission::Write);
But when compiling this we get the following error (using GCC-10):
In function ‘int main()’:
error: no match for ‘operator|’ (operand types are ‘play::File::Permission’ and ‘play::File::Permission’)
10 | play::File f2("/tmp/file1", play::File::Permission::Read | play::File::Permission::Write);
| ~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ^ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| | |
| play::File::Permission play::File::Permission
So the compiler is complaining about that it can’t do this, it’s missing an operator. This is one of the best things with scoped enums, we must tell the compiler how to handle this! So lets solve this in the next step.
Adding our first operator
Read full code on GitHub - branch: step-2
To solve the above compilation error we just need to add the operator that the compiler is asking for. We just need to do a bitwise OR.
But at this point we don’t know which type our enum Permission is. We have not specified any type so it’s up to the compiler to select one. If we don’t know the type how shall we do a type safe bitwise OR?
This is were std::underlying_type comes in handy. In short std::underlying_type will convert the enum down to its underlying data type. So:
enum class : uint8_t Test {...}; // uint8_t when using std::underlying_type.
To create our new OR (|) operator we define the following friend function. Not that we first must convert left hand side (lhs) and right hand side (rhs) into there underlying type, then do the logical OR operation before casting it all back to our correct type File::Permission.
friend Permission operator|(const Permission &lhs, const Permission &rhs);
// Note the inline
inline File::Permission operator|(const File::Permission &lhs, const File::Permission &rhs)
{
return static_cast<File::Permission>(std::underlying_type<File::Permission>::type(lhs)
| std::underlying_type<File::Permission>::type(rhs));
}
What! Writing all that code for a simple OR? Calling all these functions for a simple or? Talk about plenty of work for nothing and much more instructions to execute, or?
Well it is more code then just using a plain old |. But this code will give us much better type safety. So in my opinion it’s worth it. Regarding more code to execute? For now, just trust me (or jump to the last section in the article). The compilers are smart. Doing this compared to a plain old | is the same thing.
With this first operator we can now write code like this:
File f2("/tmp/file1", File::Permission::Read |
File::Permission::Write);
But we need more…
Adding more operators
Read full code on GitHub - branch: step-3
We can now start adding more features to our class. It would be nice to be able to see if a file is readable/writeable/executable.
bool isReadable() const;
bool isWriteable() const;
bool isExecutable() const;
bool File::isReadable() const
{
return (m_permissions & Permission::Read) == Permission::Read;
}
bool File::isWriteable() const
{
return (m_permissions & Permission::Write) == Permission::Write;
}
bool File::isExecutable() const
{
return (m_permissions & Permission::Execute) == Permission::Execute;
}
As you can see in the code above I added a new operator - this time AND (&), which we need to add to the code as well. But this is more o less just a copy of the last operator we added.
File::Permission operator&(const File::Permission &lhs, const File::Permission &rhs)
{
return static_cast<File::Permission>(std::underlying_type<File::Permission>::type(lhs)
& std::underlying_type<File::Permission>::type(rhs));
}
But what if we would like to be able to set or remove a permission on a file. Lets add the following functions:
void setReadable(const bool &readable);
void setWriteable(const bool &writeable);
void setExecutable(const bool &executable);
void File::setReadable(const bool &readable)
{
setPermisson(Permission::Read, readable);
}
void File::setWriteable(const bool &writeable)
{
setPermisson(Permission::Write, writeable);
}
void File::setExecutable(const bool &executable)
{
setPermisson(Permission::Execute, executable);
}
void File::setPermisson(const Permission &permission, const bool &value)
{
if (value) {
m_permissions = m_permissions | permission;
} else {
m_permissions = m_permissions ^ permission;
}
}
Once again we need a new operator, this time XOR (^).
inline File::Permission operator^(const File::Permission &lhs, const File::Permission &rhs)
{
return static_cast<File::Permission>(std::underlying_type<File::Permission>::type(lhs)
^ std::underlying_type<File::Permission>::type(rhs));
}
And that’s it!
Performance
TLDR;
Without any code optimizations this implementation will be a bit slower since it involves a function call, but as long as you enable -O (or more) this will produce the same assembler code and with a “unscoped” enum.
In depth performance
I wrote this simple example that I ran using Compiler Explorer. My example has four parts:
uint8_t randomValue()- This just return a random number between 0 and 4.class File- Simple example class with one scopedenumand one oldenum, Permission and BadPermission. It also has a “OR” operator.File::Permission test1()- Function that takes two randomFile::Permissionand return the OR value of the two.File::BadPermission test2()- Function that takes two randomFile::BadPermissionand return the OR value of the two.
#include <type_traits>
#include <random>
uint8_t randomValue()
{
std::random_device dev;
std::mt19937 rng(dev());
std::uniform_int_distribution<std::mt19937::result_type> dist(0,4);
return dist(rng);
}
class File
{
public:
enum class Permission { Read = 1, Write = 2, Execute = 4 };
enum BadPermission { Read = 1, Write = 2, Execute = 4 };
friend Permission operator|(const Permission &lhs, const Permission &rhs) {
return static_cast<File::Permission>(std::underlying_type<File::Permission>::type(lhs)
| std::underlying_type<File::Permission>::type(rhs));
}
};
File::Permission test1()
{
const auto p1 = static_cast<File::Permission>(randomValue());
const auto p2 = static_cast<File::Permission>(randomValue());
return p1 | p2;
}
File::BadPermission test2()
{
auto p1 = static_cast<File::BadPermission>(randomValue());
auto p2 = static_cast<File::BadPermission>(randomValue());
return p1 | p2;
}
By looking at the assembler code for function test1() and compare it with test2() it’s possible to see which of the to functions performs the best.
No optimization
Using Compiler Explorer and x86-64 GCC 11.2 I get the following result.
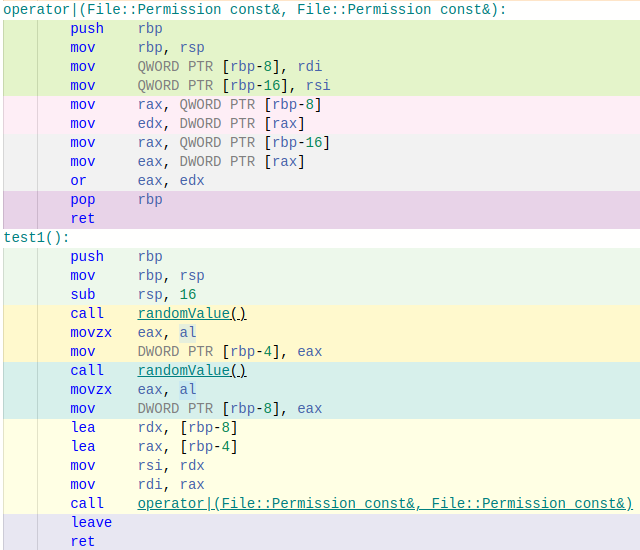
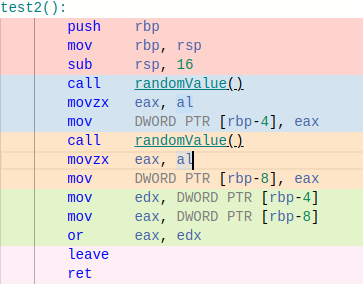
You don’t need to be an assembler guru to see that the performance differs. Our scoped enum (function test1() and operator friend Permission operator|(const Permission &lhs, const Permission &rhs)) will need much more assembler instructions to solve the problem. The main issue here is that it need to call the operator function. But…
With -O optimization
By just enabling optimization on the code we get this:

Now we have the exact same assembler code for function test1() and test2(). Once again you don’t need to be an assembler guru to understand that running function test1() will do the exact same thing as running function test2(). This shows that using scoped enum does not decrease the performance of bit flags/patterns compared to not using it, we just need a few lines of extra code!